在當今的軟件開發和運維實踐中,監控與調優是保障系統穩定高效運行的關鍵環節。本文將系統性地探討兩個重要主題:如何在本地開發環境中查看和分析JVM的垃圾回收(GC)日志以優化應用性能,以及如何使用ELK技術棧(Elasticsearch、Logstash、Kibana)構建一個能夠處理TB級別日志數據的監控系統,并涵蓋數據處理與存儲服務的相關設計思路。
一、本地運行中如何查看與分析GC日志
GC日志是診斷JVM內存問題、優化垃圾回收性能的重要依據。在本地開發或測試環境開啟并查看GC日志,通常只需在JVM啟動參數中進行配置。
1. 開啟GC日志記錄
* 對于JDK 8及之前的版本,常用的啟動參數如下:
`bash
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
`
-Xloggc 用于指定GC日志文件的輸出路徑。
* 對于JDK 9及更高版本,推薦使用統一的JVM日志框架,參數更為簡潔強大:
`bash
-Xlog:gc*,gc+age=trace,safepoint:file=
`
此命令可以輸出詳細的GC信息,并支持日志輪轉(保留5個文件,每個最大10MB)。
- 查看與分析GC日志
- 直接查看:對于簡單的日志,可以直接使用文本編輯器或命令行工具(如
tail -f)查看實時輸出的日志,關注Full GC的頻率和持續時間。
- 使用分析工具:對于復雜的性能分析,推薦將日志文件導入可視化工具,它們能更直觀地展示GC事件、內存變化趨勢和暫停時間。
- GCeasy (https://gceasy.io/):一個在線的免費GC日志分析器,上傳日志文件即可獲得詳盡的分析報告和可視化圖表。
- GCViewer:一個開源的離線分析工具,可以從GitHub獲取。
- JVM內置工具:如
jstat命令可以實時監控GC情況,但不如日志分析全面。
通過分析GC日志,可以定位是否存在頻繁的Full GC、Young GC暫停時間過長、內存泄漏等問題,進而調整堆大小(-Xms, -Xmx)、新生代與老年代比例(-XX:NewRatio)或選擇合適的垃圾收集器(如G1、ZGC)來優化應用。
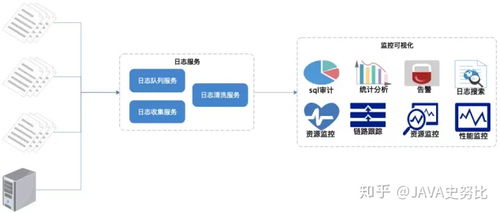
二、使用ELK搭建TB級日志監控系統:數據處理與存儲服務設計
當系統規模擴大到生產環境,每日產生TB級的日志時,一個集中、可擴展的日志監控系統至關重要。ELK Stack是目前最流行的解決方案之一。
- 核心組件與架構
- Elasticsearch:負責日志數據的分布式存儲、索引和搜索。它是系統的核心存儲與計算引擎。
- Logstash:負責日志的收集、過濾、轉換和輸出。它可以從多種來源(文件、Kafka、Redis等)攝取數據,進行解析(如解析JSON、分割文本)后發送到Elasticsearch。
- Kibana:提供數據可視化界面,用于日志查詢、儀表盤制作和監控告警。
- 擴展組件:在TB級場景下,通常會在日志生產端和Logstash之間引入 Beats(輕量級數據采集器,如Filebeat)和 消息隊列(如Kafka或Redis),以解耦、緩沖并提高可靠性。
- TB級系統搭建與優化要點
- 集群化部署:所有組件都應集群化部署,避免單點故障。
- Elasticsearch集群:根據數據量、查詢負載和可用性要求,規劃足夠數量的主節點、數據節點和協調節點。TB級數據通常需要至少3個主節點和多個數據節點。
- Logstash集群:部署多個Logstash實例進行負載均衡。
* 引入消息隊列(Kafka):
架構變為:應用日志 -> Filebeat -> Kafka -> Logstash集群 -> Elasticsearch集群。
Kafka能應對日志洪峰,保證數據不丟失,并允許下游消費者(Logstash)按自身處理能力消費數據。
- Elasticsearch數據處理與存儲優化:
- 索引設計:采用基于時間的索引策略(如
logs-app-2024-08-01),便于按時間范圍管理和過期刪除數據。使用索引模板統一設置映射和分片數。
- 分片與副本:合理設置索引的主分片數(影響分布式處理能力)和副本數(影響數據可靠性和讀性能)。單個分片大小建議在30GB-50GB之間。
- 冷熱數據分層:使用SSD存儲熱數據(近期高頻查詢),使用大容量HDD存儲溫冷數據(歷史低頻查詢),通過Elasticsearch的索引生命周期管理(ILM)策略自動轉移。
- 數據預處理:在Logstash或Elasticsearch Ingest Node中,盡可能地對日志進行結構化解析(如提取IP、時間戳、錯誤級別),避免在原始文本上查詢,大幅提升查詢效率。
- 性能與穩定性:
- 為Elasticsearch數據節點配置充足的內存(堆內存不超過31GB,預留一半內存給操作系統文件緩存)。
- 監控集群健康狀態、節點負載、磁盤使用率和查詢延遲。
- 設置索引的滾動(Rollover)和壓縮(Force Merge)策略。
- 利用Kibana的告警功能或集成第三方告警系統(如Prometheus Alertmanager)實現異常監控。
3. 數據處理與存儲服務
在廣義的日志監控系統中,“數據處理與存儲服務”可能超出ELK本身,涉及更下游的環節:
- 長期歸檔:對于需要合規性長期保存的日志,可以定期將Elasticsearch中的冷索引快照(Snapshot)備份到對象存儲(如AWS S3、MinIO)或HDFS。
- 數據分析平臺集成:可以將Elasticsearch中的數據通過Logstash或Spark等工具,同步到數據倉庫(如Hive)或數據分析平臺進行更深度的離線分析和報表生成。
- 安全與權限:通過Elasticsearch的安全特性(如X-Pack)或外部代理,實現基于角色的訪問控制(RBAC),確保日志數據的安全。
****
從本地開發的GC日志微觀分析,到生產環境TB級日志的宏觀監控,體現了軟件生命周期中不同階段的性能治理需求。本地GC調優是提升單應用性能的基礎,而ELK為核心的日志監控系統則是保障大規模分布式系統可觀測性的基石。通過合理的架構設計、組件配置和優化策略,ELK能夠穩定高效地處理海量日志,為故障排查、性能分析和業務洞察提供強大的數據支持。在實際搭建時,建議從小規模開始,隨著數據量和需求的增長,逐步迭代架構,引入消息隊列、集群化和分層存儲等高級特性。